Lift3D Foundation Policy: Lifting 2D Large-Scale Pretrained Models for Robust 3D Robotic Manipulation
Lift3D Policy
Abstract
3D geometric information is essential for manipulation tasks, as robots need to perceive the 3D environment, reason about spatial relationships, and interact with intricate spatial configurations. Recent research has increasingly focused on the explicit extraction of 3D features, while still facing challenges such as the lack of large-scale robotic 3D data and the potential loss of spatial geometry. To address these limitations, we propose the Lift3D framework, which progressively enhances 2D foundation models with implicit and explicit 3D robotic representations to construct a robust 3D manipulation policy. Specifically, we first design a task-aware masked autoencoder that masks task-relevant affordance patches and reconstructs depth information, enhancing the 2D foundation model’s implicit 3D robotic representation. After self-supervised fine-tuning, we introduce a 2D model-lifting strategy that establishes a positional mapping between the input 3D points and the positional embeddings of the 2D model. Based on the mapping, Lift3D utilizes the 2D foundation model to directly encode point cloud data, leveraging large-scale pretrained knowledge to construct explicit 3D robotic representations while minimizing spatial information loss. In experiments, Lift3D consistently outperforms previous state-of-the-art methods across several simulation benchmarks and real-world scenarios.
Overview
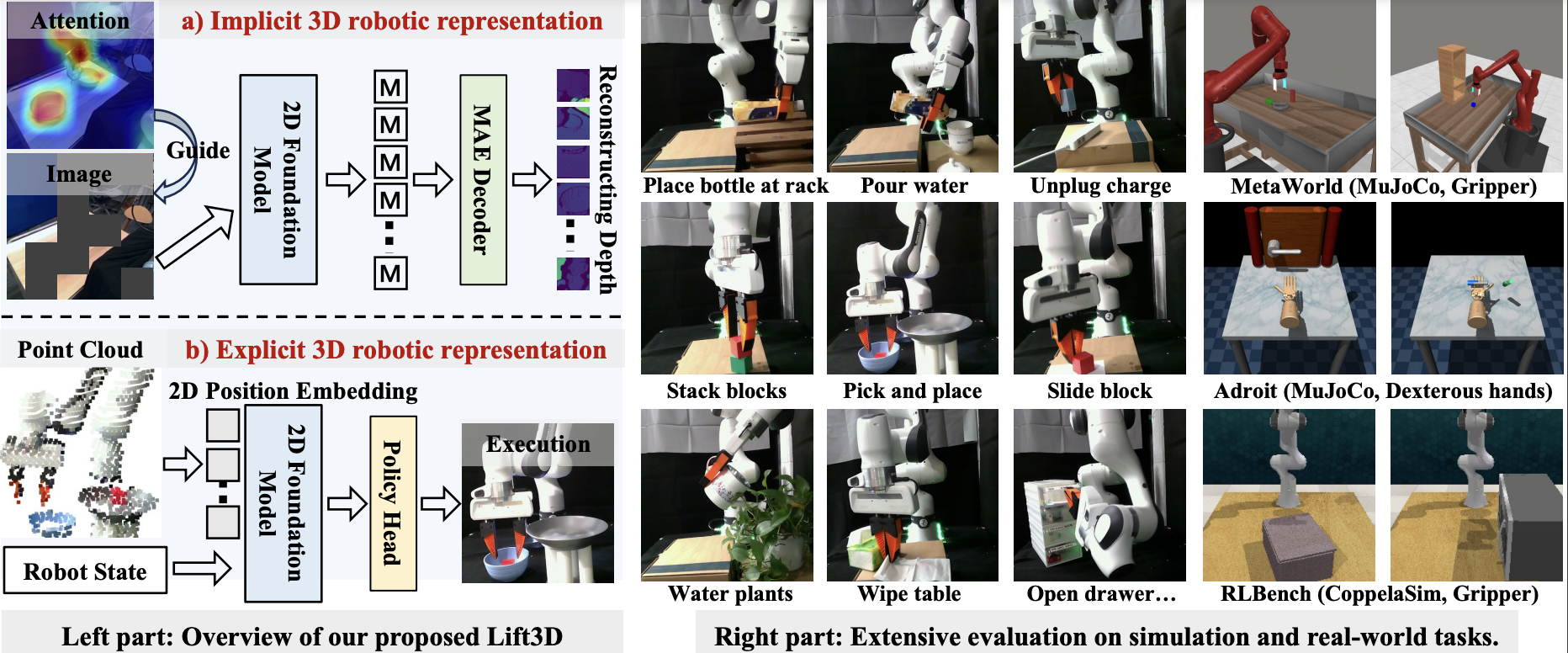
Lift3D empowers 2D foundation models with 3D manipulation capabilities by refining implicit 3D robotic representations through task-related affordance masking and depth reconstruction, while enhancing explicit 3D robotic representations by leveraging the pretrained 2D positional embeddings to encode point cloud. Lift3D achieves robustness and surprising effectiveness in diverse simulation and real-world tasks.
Lift3D pipeline
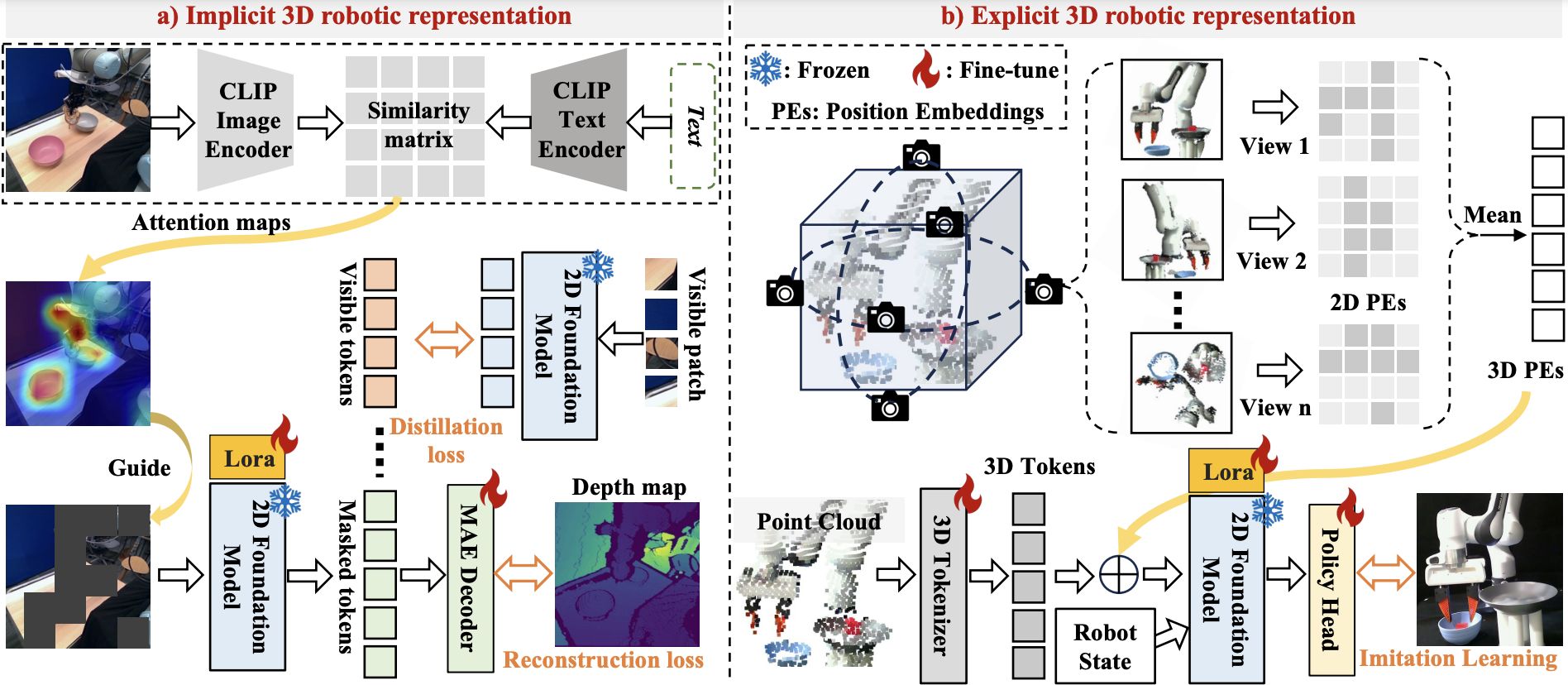
For implicit 3D robotic representation, we leverage CLIP to offline extract image attention maps based on task descriptions, which are back-projected onto the 2D input to guide the MAE masking. We then input the visible tokens into the 2D foundation model to extract features. The masked tokens and encoded visible tokens are processed by the MAE decoder for depth reconstruction, enhancing 3D spatial awareness. Meanwhile, the encoded visible tokens are also distilled using corresponding features from the off-the-shelf pretrained model to mitigate catastrophic forgetting.
For explicit 3D robotic representation, we first project the point cloud data onto multiple virtual planes, establishing a positional mapping between the 3D input points and the 2D positional embeddings (PEs) on each virtual plane. After mapping, we average the 2D PEs corresponding to each 3D patch to form a unified positional indicator(3D PEs), which is then integrated with the 3D tokens.These 3D tokens are generated by feeding the point cloud into a lightweight 3D tokenizer. Finally, the output features from the 2D foundation model are processed through a policy head to predict the pose for imitation learning.
Lift3D in the real world
In our real-world setup, we conduct experiments using a Franka Research 3 arm, with a static front view captured by an Intel RealSense L515 RGBD camera. We perform ten tasks: place bottle at rack, pour water, unplug charger, stack blocks, pick and place, slide block, water plants, wipe table, open drawer, and close drawer. These tasks involve various types of interacted objects and manipulation actions. For each task, 40 demonstrations are collected in diverse spatial positions, with trajectories recorded at 30 fps. We select 30 episodes and extract key frames to construct the training set for each task.
Real-world experiment setup
In our real-world setup, we conduct experiments using a Franka Research 3 (FR3) arm, with a static front view captured by an Intel RealSense L515 RGBD camera. Due to the relatively short length of the FR3 gripper fingers, which makes it challenging to perform certain complex tasks, we 3D print and replace the original gripper with a UMI gripper. Our FR3's controller version is 5.6.0, libfranka version is 0.13.3, Franka ROS version is 0.10.0, and Ubuntu version is 20.04 with ROS Noetic. All the videos shown in our demos are based on real-world tests of our proposed model. The FR3 is in a green light state when in execution mode, with the FCI switch set to 'on', as shown in the figure below. If you have any questions about our real-world experiments, feel free to ask.
BibTeX
@misc{jia2024lift3dfoundationpolicylifting,
title={Lift3D Foundation Policy: Lifting 2D Large-Scale Pretrained Models for Robust 3D Robotic Manipulation},
author={Yueru Jia and Jiaming Liu and Sixiang Chen and Chenyang Gu and Zhilue Wang and Longzan Luo and Lily Lee and Pengwei Wang and Zhongyuan Wang and Renrui Zhang and Shanghang Zhang},
year={2024},
eprint={2411.18623},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2411.18623},
}